The HTTP Protocol
HTTP has played a fundamental role in the success of internet, its reliable communication and flexibility to transmit any kind of data are some of the reasons why the Hypertext Transfer Protocol (HTTP) became the preferred protocol among servers and clients around the world, after all you are using HTTP while reading this post. In this article I want to give a brief idea about how this protocol works. But first let’s explain what is a protocol.
Protocols
When two computers establish a communication channel they need to follow a set of rules to understand each other, these set of rules are known as a protocol, thus when you browse a website we can say your computer is following the HTTP rules to communicate with other computer following the same rules. Protocols come in all sizes and flavors, and are used in many contexts, for example your e-mail provider (say gmail, hotmail or whatever) use pop3, imap and smtp to manage your e-mail, the ssh protocol is used to access to another machine securely, ftp allows you to get a file from another computer. Most of the mainstream protocols follow a client-server scheme that is, one computer or program assumes the role of providing the content is asked for (the server), and the other makes the request to get the desired content (the client), for example to read this article your browser (the client) had to ask another computer running a program called nginx (the server) to provide this content.
The HTTP rules
Every Message in HTTP is structured in three main parts:
- Start Line: Which describes the message transaction.
- Headers: Are attributes that give information about the message.
- Body (optional): It is the document or content of the message.
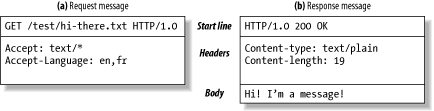
As the image above suggest, client messages are called requests and messages that come from the server are called responses.
To illustrate the rules behind HTTP I’m going to use curl, a terminal multi protocol client, that can prompt the hole process of an HTTP transaction. So here we go:
user@client:~ $ curl -vs http://example.org
* Trying 93.184.216.34:80...
* Trying 2606:2800:220:1:248:1893:25c8:1946:80...
* Immediate connect fail for 2606:2800:220:1:248:1893:25c8:1946: Network is unreachable
* Connected to example.org (93.184.216.34) port 80 (#0)
> GET /index.html HTTP/1.1
> Host: example.org
> User-Agent: curl/7.84.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Accept-Ranges: bytes
< Age: 233829
< Cache-Control: max-age=604800
< Content-Type: text/html; charset=UTF-8
< Date: Sun, 31 Jul 2022 15:33:22 GMT
< Etag: "3147526947"
< Expires: Sun, 07 Aug 2022 15:33:22 GMT
< Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT
< Server: ECS (mic/9AF5)
< Vary: Accept-Encoding
< X-Cache: HIT
< Content-Length: 1256
<
...
[website content]
...
“>” lines correspond to the request sent by curl (the client) to example.org (the server) and “<” lines are the response from example.org machine to the client, lines starting with “*” are just log messages from curl that we will ignore.
The Client Request
In every HTTP transaction the client starts the conversation, in our example the client sent the following message request:
GET /index.html HTTP/1.1
Host: example.org
User-Agent: curl/7.84.0
Accept: */*
The start line “GET /index.html HTTP/1.1” has the form “<method> <resource> HTTP/<version>”. The method describes the transaction that will be made, in this case GET method means that the client will ask for the document (or resource) index.html.
The most common methods in a request are:
- GET: Get a resource from the server
- POST: Send data to the server for processing
- PUT: Send data to the server to Storing it
- HEAD: Just get the headers for an asked resource.
- DELETE: Remove a file stored in the server
The headers “Host: example.org”, “User-Agent: curl/7.84.0” and “Accept: */*” are attributes that work together with the; method GET to determine what to do with the message, Host specifies from which server the data will be retrieved, User-Agent tells the server information about the client program an its environment, and Accept provides information about what kind of data the client is expecting to receive, in this case curl will accept any kind of data, but if the client is just accepting html files the header could be changed for “Accept:text/html”.
Because the client is asking for getting a document with the GET there is nothing to send to send to the server, so the body is omitted, even in the case that the body is sent to the server, it will discard that content because of the GET method. To end the request message curl writes a final blank line
The Server Response
On the server side the start line “HTTP/1.1 200 OK” response means that the server will accept the client request, 200 OK status code gives information about how the request was processed, 2xx codes indicates that the request was done correctly, other status codes are:
- 3xx: the server tells to the client to go to another place to get the document.
- 4xx: these codes mean that there was an error in the client side, like requesting a document without the proper header values or the well known 404 which means that the client is asking for a document that doesn’t exist.
- 5xx: This one means that there is something wrong on the server.
On the headers part the most important ones are “Content-Type: text/html; charset=UTF-8” and “Content-Length: 1256”, the others usually change from server to server. Content-type header specifies what kind of data will be provided to the client, in this case is a text html file, but it can also be an image/jpeg file or an audio/wav file, just thing in any kind of data a good HTTP server will support it. Content-Length tells the client about the size of the body in bytes, this information is crucial because it helps the client to figure out when to stop listening the server response.
To end the headers part of the response the server will write a blank line followed by the body which has the requested document, after sending the document the response will be finished with a new blank line and the conversation between client and server will be closed.
Conclusion
A key feature of HTTP is its structural simplicity, the start line allow servers an clients get an idea about what is happening with an HTTP transaction, while the headers specify its details.
Further Reading
If you want to grasp into the details of HTTP I recommend you to take a look at the HTTP The definite Guide Book and Mozilla website, the first is a pretty comprehensive book to learn about the protocol while the second provides a great source of reference information.